On the Evaluation Trials in Speaker Verification
Lantian Li, Di Wang, Dong Wang
Abstract
Evaluated trials are the main instrument to probe the performance of a speaker verification system. However,
careful and systematic study on evaluation trials is rare, including their representativeness,
consequence of different settings, and how to design trials that better reveal technical innovation.
This paper presents the first systematical study on evaluation trials.
(1) Firstly, we propose the concept of C-P map, where the performance of a verification system with different trial configs is shown in a 2-dimensional map. This offers a global picture for the performance of a system, hence can be used as a powerful tool for system analysis, tuning, and comparison.
(2) Furthermore, we advocate focusing on hard trials as they represent the core challenge that present research has not resolved. We present two approaches to retrieving hard trials, one based on system ensemble and the other based on support vectors. We studied the properties of the retrieved hard trials from the perspectives of both machines and humans. Experimental results demonstrated that the hard trials are indeed very challenging even for today's most powerful models, hence should be the focus of future research.
Part I: C-P map
1. Introduction
We firstly conduct a comprehensive study on evaluation trials. Our
study shows that an ASV system may exhibit quite different performance
when probed by different settings of trials, and so resorting to any particular
setting will lead to biased evaluation. This inspired the idea of evaluating ASV
systems with multiple and diverse settings of trials. The outcome is a new
evaluation tool called Config-Performance (C-P) map, which represents
performance results (e.g., in terms of EER) in a 2-dimensional picture, each
location corresponding to a particular setting of trials called a trial config.
We will show that C-P map is a powerful tool for system analysis, tuning, and
comparison.
2. Basic concepts
(1) Trial config: Given a set of enrollment/test utterances, a trial config is
defined as a subset of trials selected to test against the ASV system.
(2) C-P map: We evaluate the target system at different trial configs and show
the results in a 2-dimensional picture called a config-performance (C-P) map.
In this map, the x-axis corresponds to subsets of positive trials and the y-axis
corresponds to subsets of negative trials, so each location (x; y) on the map
represents a particular trial config. Let the color at (x; y) represent the primary
performance measurement such as EER, we obtain a C-P map.
Example: a C-P map of an i-vector system.

(3) Delta C-P map: C-P map shows performance with various trial configs and can be used to compare two systems in a thorough way. This comparison is better performed with delta C-P map, where the color at each location shows the relative change ratio (RCR) of two systems at each location (x; y), formally written by:
RCR_t,r(x,y) = - { CP_t(x,y) - CP_r(x,y) } / CP_r(x,y), where CP_t(x,y) and CP_r(x,y) denote the C-P map of the test system and a reference system.
Example: a Delta C-P map of the reference i-vector system and the test x-vector system.
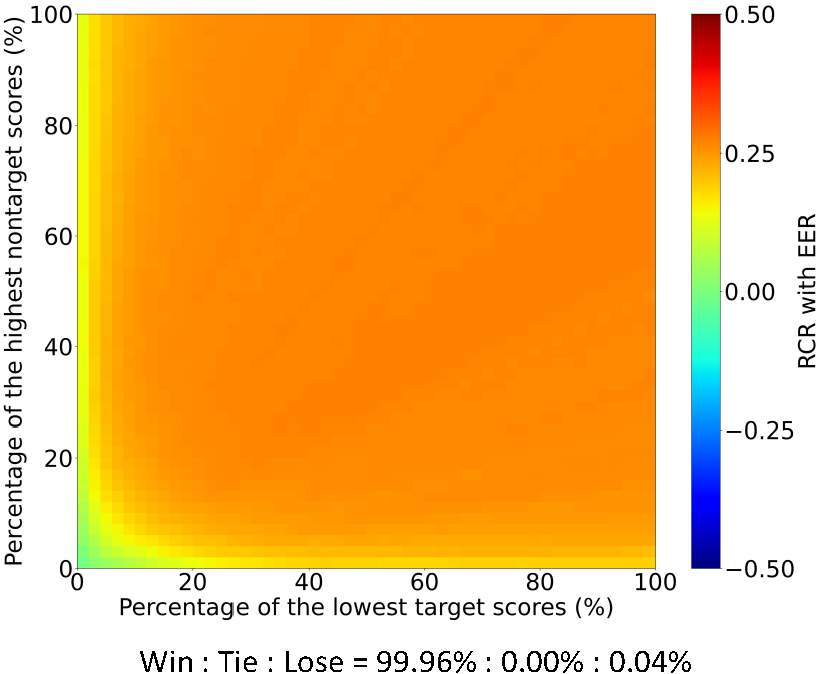
3. The Value of C-P map and Delta C-P map
Roadmap of speaker recognition techniques

It can be seen that these C-P maps show clearly how the technical advance tackles the ASV task gradually, in particular how hard trials are solved step by step. The delta C-P maps also show that some techniques are truly revolutionary.
This demonstrates that C-P map is a powerful tool for system/technique analysis and comparison.
The source code for C-P map generation have been released here.
Part II: Hard Trials
1. Why hard trials?
We advocate paying attention to hard trials because (1) it reveals the unsolved difficulties in ASV; (2) it leads to less biased comparison among techniques.
2. How to retrieve hard trials?
(1) Ensemble approach: To choose several systems to test the trials and choose the trials that all the systems feel hard.
The pre-request of this ensemble approach is that the commonly-agreed hard trials exist.
(2) SVM approach: For each trial, we collect the scores produced by a set of baseline ASV systems, and these scores form a score vector. Then we train a support vector machine (SVM) with these score vectors of all these trials and treat the trials corresponding to the support vectors as hard trials.
These hard trials we retrieved have been published online.
3. Hard trials retrieval
Hard trials retrieved by different methods

There are several observations: (1) Even with the strict ensemble approach, we can still get some hard trials. This indicates that some trials are truly hard. (2) The SVM approach produces much more hard trials. These trials are not as hard as the ones obtained from the ensemble approach, but are still confusing from the perspective of SVM. (3) The results of the intersection and union imply that the trials derived from the ensemble approach largely form a subset of those derived from the SVM approach.
4. Performance on hard trials
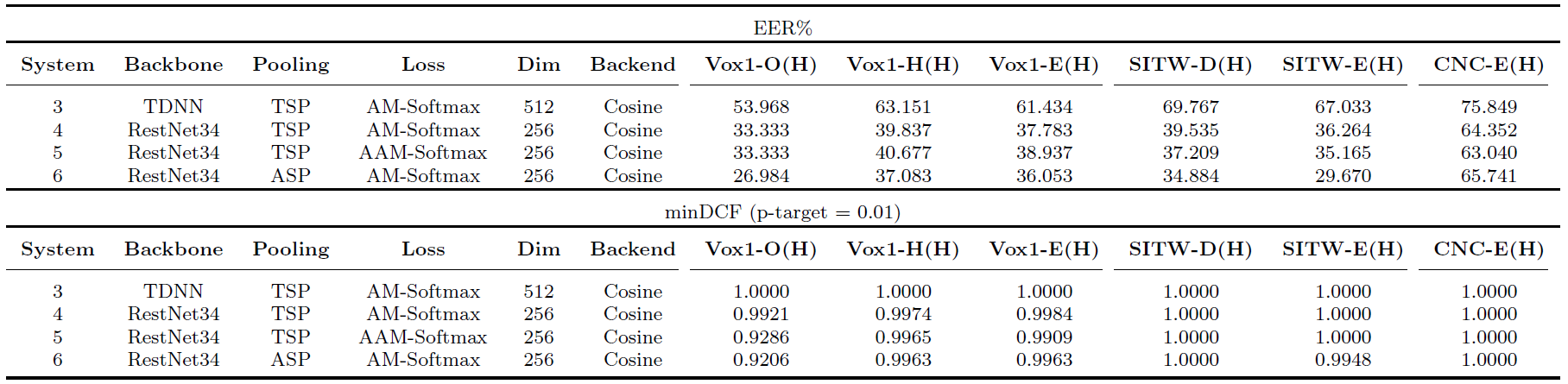
(1) Results on ensemble-derived hard trials
(2) Results on SVM-derived hard trials
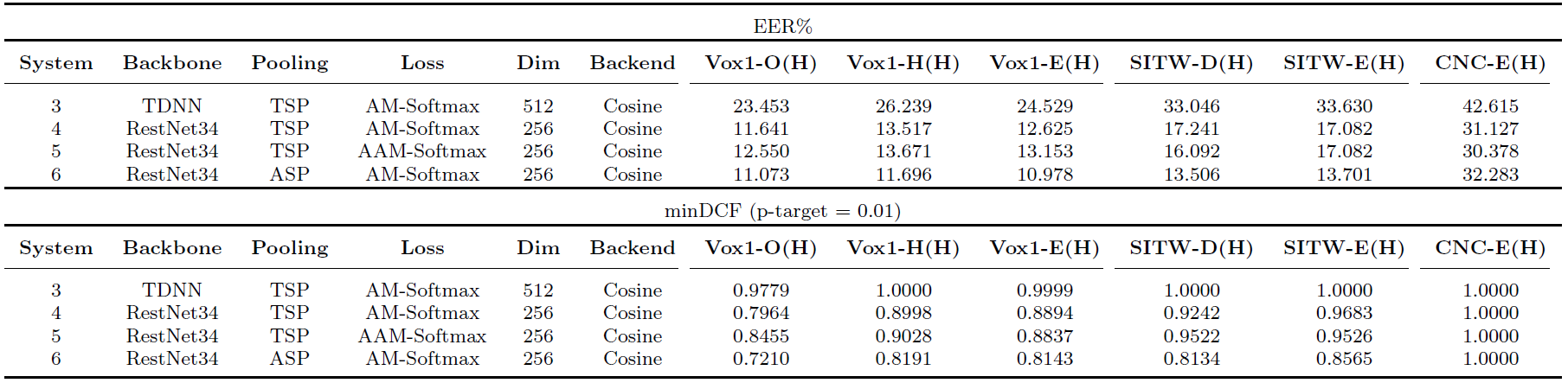
It can be observed that compared to the results on the full trials, the results on the two sets of hard trials are significantly reduced, in terms of both EER and minDCF. This indicates existing speaker verification techniques are far from satisfactory on hard trials. In addition, compared to the ensemble-derived hard trials, the performance on the SVM-derived hard trials looks much better. This is expected as the SVM approach treats all the trials close to the decision boundary as hard trials, not only the trials on the wrong side of the boundary.
5. Properties of hard trials
(1) Machine perception: what hard trials look like. We first compute the Kendall's τ distance between each pair of systems, and then plot all the systems in a 2-D picture using the classical (non-metric) multi-dimensional scaling (MDS).
MDS visualization of the relations of 8 baseline systems on easy, normal
and hard trials.
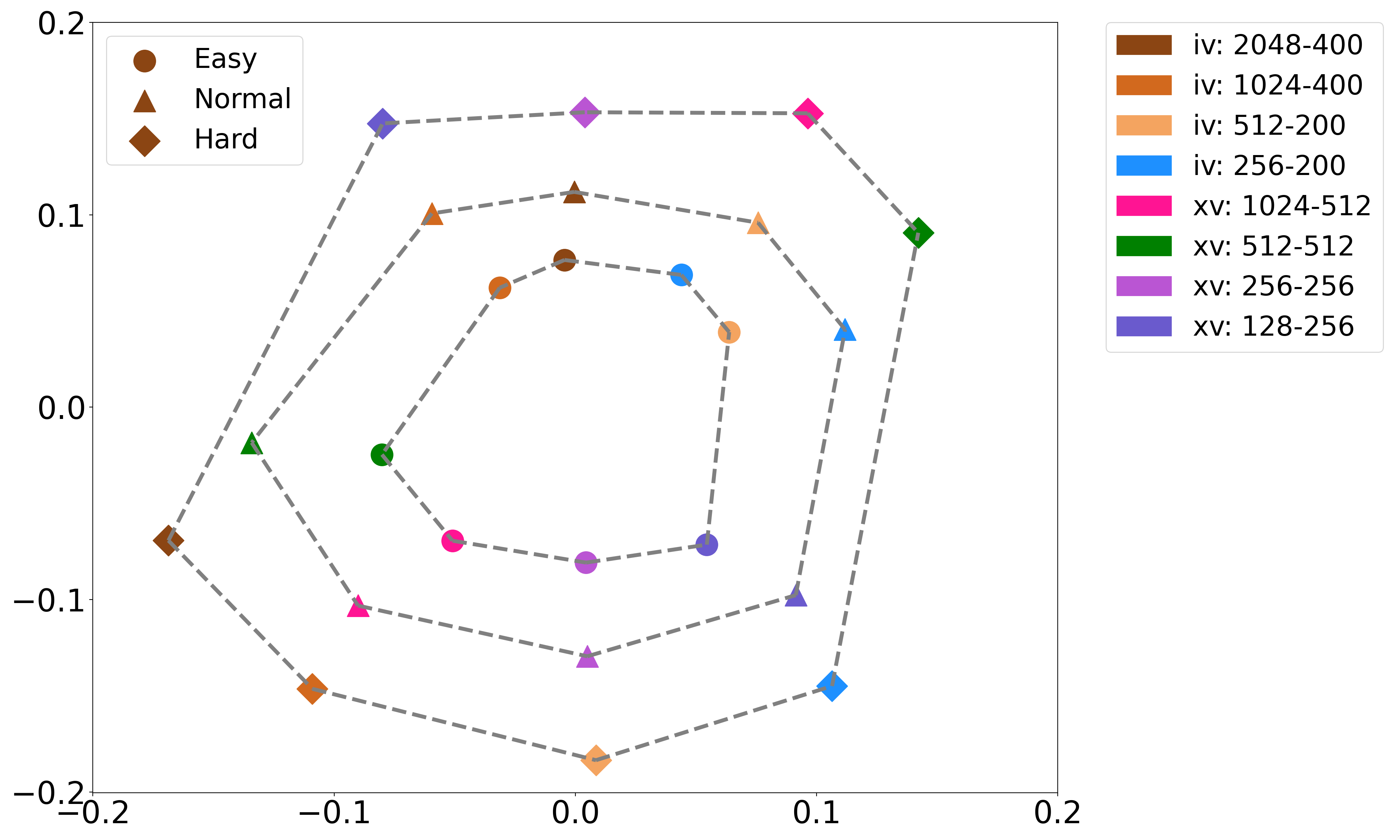
It can be observed that as the trials get harder, the distance between different systems becomes larger. This observation suggests that for hard trials, the opinions of different systems are more diverse compared to those on easier trials, indicating that they are confused when processing hard trials.
(2) Human perception: what hard trials sound like. The trials were assigned to the listeners who were asked to recognize whether the pair of utterances in each trial is from the same speaker or not. There were 200 Chinese listeners participating in the test, and each listener completed 100 trials.
Behavior of Human vs. Machine on easy/normal/hard trials.
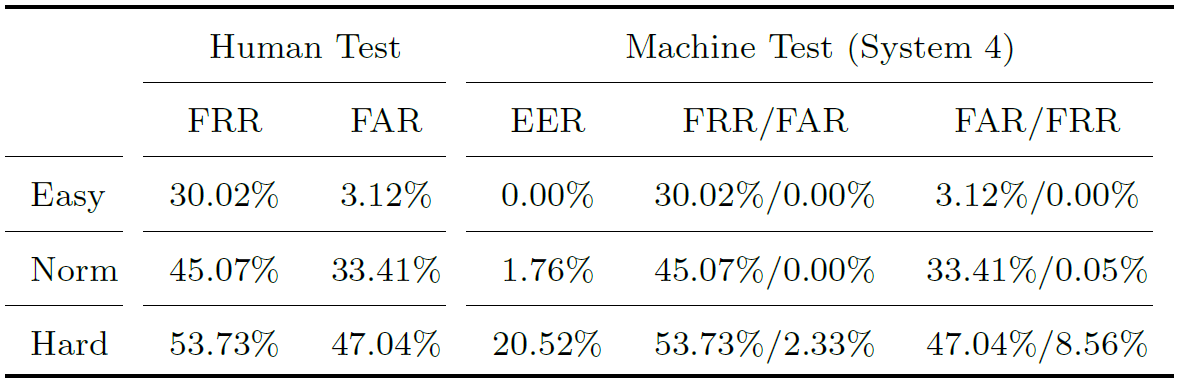
Firstly, it can be observed that human listeners and machines behave consistently on different speaker recognition tasks: whenever machines feel hard, human listeners feel hard as well. This is an interesting observation and offers a strong evidence that some trials are truly hard. Besides, we can observe that machines generally outperform human listeners, on all the three types of trials.
(3) Hard trials and label errors: if some hard trials are hard because they were incorrectly labelled. To address the concern, we perform human check on hard trials focusing on CN-Celeb.E which contains complex multi-genre trials. In particular, we selected the 1,296 target hard trials in the Ensemble SVM set, and then conducted a listening check to verify whether the enroll and test utterances were from the same speaker. Finally, we checked that there were 52 label errors in the 1,296 trials. A cleaned CN-Celeb.E trial set was constructed by removing these mislabelled trials.
Results with System 4 on trials with/without cleaned up.
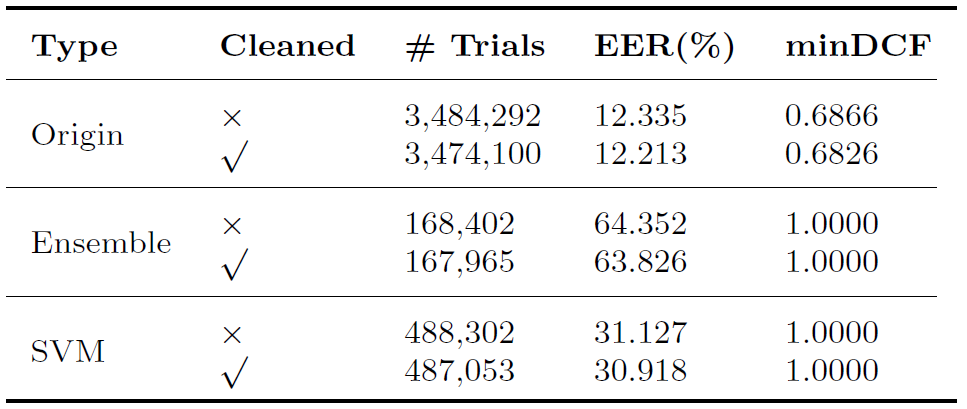
It can be observed that performance is slightly improved with the label errors removed. From one perspective, it confirms the existence of label errors but the impact is not predominant, and most of the hard trials are truly hard. From another perspective, this experiment demonstrated that the hard trials retrieval approach could be used as a good way of data quality inspection, in particular to identify potential label errors.
Back to Top